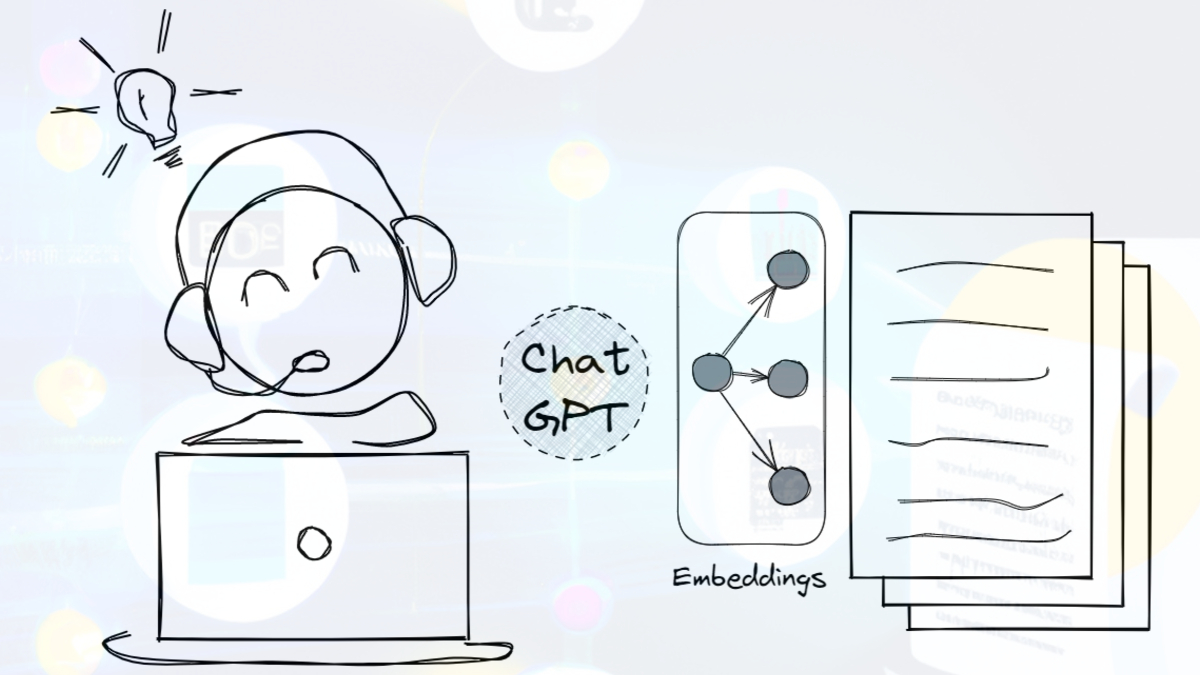
One of the most sought-after AI systems is one where you can easily query a knowledgebase via a ChatGPT-like interface.
Basic Q&A with Embeddings
Since you can't fine-tune the newer, more conversational models like the ChatGPT API, embeddings are how you "train" them on your proprietary knowledge base.
To create your embedding system, you must first embed your documents and store both the document and embedding vectors in a database.
Then, when the user submits a query, their question is embedded, and the embedding vector is used to surface semantically similar documents. The content of these documents is merged with the question, and the result is used as a prompt to the ChatGPT or GPT-3 APIs.
This way, the language model answers your questions in the context of documents retrieved via the embedding system.

Hypothetical Document Embeddings (HyDE)
Hypothetical Document Embeddings (HyDE) is an embedding search technique that begins by generating a hypothetical answer and then using that hypothetical answer as the basis for searching the embedding system. It is a proven way to improve the accuracy of question answering by surfacing content that better matches the underlying intent of the query.

The Art of Embedding
Documents can and should be parsed, sliced and diced, into smart pieces that maximize their future value. There are nearly infinite ways to design these pieces, or "embedding inputs," and their design will significantly impact your performance.
Is your investment in AI mission-critical? Schedule a consultation.