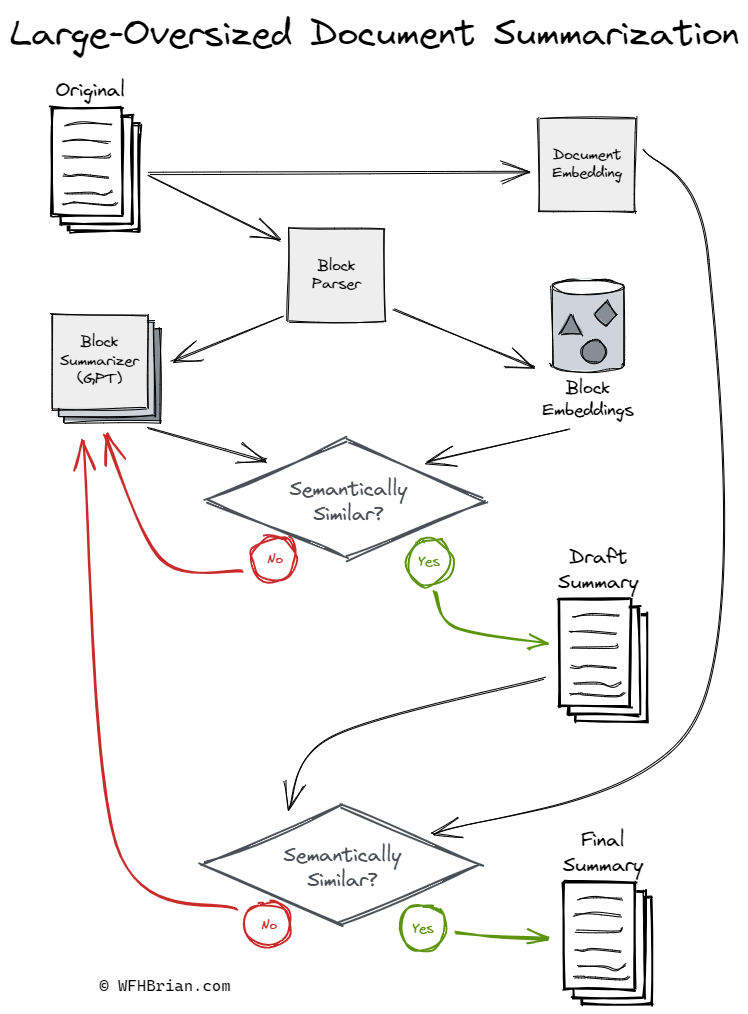
I'm excited to share a powerful method for accurately summarizing large documents that exceed the input size limit of GPT-4. I've designed a diagram to visually illustrate this approach, which leverages embeddings to check the semantic similarity of summarized blocks (chunks). This iterative process ensures that each block reaches a desired similarity threshold before being combined into a draft summary. This is then compared to the original document to maintain overall semantic coherence.
Especially for extra-large documents, this method may need to be executed recursively. In such cases, the document is first segmented into the fewest possible blocks that fit within the size limit for the embedding model. Then, our approach is applied to each segment to output a single document that serves as a semantic reference point for additional iterations. This allows us to reduce the size of the document further while still preserving its core meaning.
I invite you to explore the diagram below, which provides a visual guide to this process.